
¿Se indexan o no se indexan? ¿Se bloquean o se dejan que se rastreen? ¿Es rentable tener muchas URLs rastreables cuando la mayoría de las visitas se las llevan las últimas URLs? Discutamos. TL;DR: Depende. 😀 Lo siento. De verdad. Lo que os vamos a contar aquí es como llegar a tomar una decisión sobre la hemeroteca de un medio de comunicación. Ahora tu interpreta tus datos y toma tu la decisión.
Gracias
Antes de nada, damos las gracias a OnCrawl (del que Señor Muñoz y yo mismo somos uno de sus embajadores en España) hemos podido exprimir la herramienta a conciencia con un site inmenso. Este post forma parte de una presentación que harán mis compañeros Jose Miguel Moreno y Sergio Redondo en el Congreso SEO Profesional 2018 (esperamos veros por allá).
Gracias al medio por la generosidad y gracias a OnCrawl por su predisposición y ayuda.
Estado del sitio: noticias, noticias y más noticias
Iba a llamar al post ¡Cómo mola esto! pero creo que no es de recibo (además de bastante malo desde el punto de vista SEO). Imaginad un sitio de noticias: 365 días de noticias. Una media de 30 noticias al día.
La importancia de la organización en el descubrimiento de patrones.
Es obvio que una de las cuestiones fundamentales desde el punto de vista SEO es el descubrimiento de patrones. Estos patrones nos permiten atacar secciones de forma mucho más eficiente, consiguiendo relaciones entre secciones para maximizar el impacto semántico de los contenidos que enlazamos. Así podemos relacionar, por ejemplo, deportistas con sus equipos, pasados y actuales, actores con sus películas, documentales, series u obras de teatro, políticos con sus gobiernos o partidos,… Si conseguimos maximizar la semántica estaremos dando señales muy potentes a Google de la relevancia de esos enlaces.
Pero ¿Cómo descubrimos los patrones?
Claro está que conocer el sitio nos hace poder identificar los patrones de forma eficiente y, por ende, organizarlos. Así pues, cuando organizamos nuestro contenido (sin duda una de las grandes ventajas de OnCrawl, que nos permite organizar por secciones, por grupos de páginas) cuando una web como la nuestra presenta varias tipologías (noticias, etiquetados y páginas especiales de información sobre determinados verticales,…) es fundamental para entender el desempeño de nuestra web.
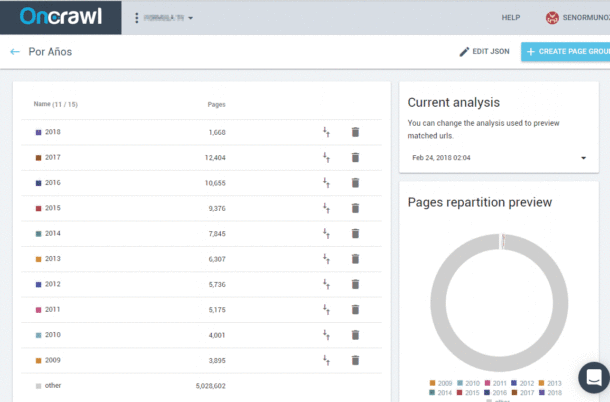
Sigamos con el ejemplo. Sumando el agrupamiento de nuestros contenidos, con los datos que tenemos de los logs del sistema, las estructuras de carpetas y subcarpetas y lo que conocemos de la web, la fotografía es la siguiente:
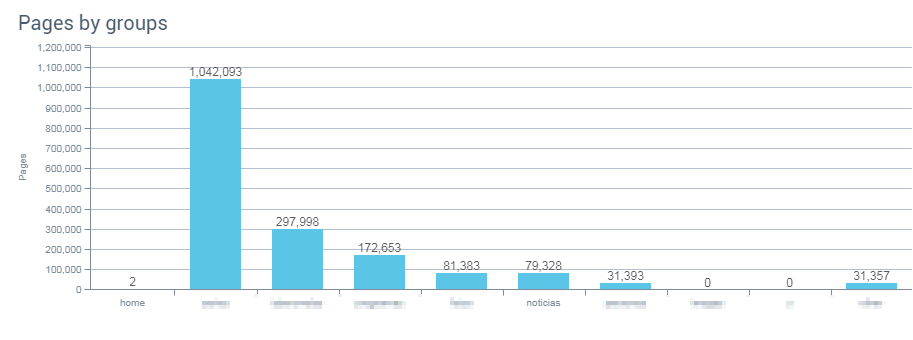
Páginas por grupos: El bloque noticias es el 5º en orden de importancia dentro de la web.
Como se ve, el bloque de noticias es superado ampliamente en número de páginas por otros cinco bloques anteriores.
Al ser un medio de comunicación, el problema viene en intentar entender el por qué el bloque de noticias no es el máximo y el más relevante, pero eso es para otro post porque estudiada la web, puede tener sentido. Centrémonos en la parte de los artículos, que es de lo que trata este texto.
La lógica nos dice que el número de visitas anual depende mucho de las noticias de ese mismo año, por lo que tendríamos que intentar entender cómo se comporta Google con respecto a las noticias antiguas y cómo se comporta el usuario (si le interesan las noticias antiguas, sin ir más lejos).
Los medios, las noticias y el QDF
Cómo somos un medio de comunicación tenemos una estrategia de inundación de keywords muy repetitiva (si escribimos sobre los ERE de Andalucía, sobre el Golpe de Estado en Cataluña, sobre la Gurtel o sobre el Cádiz CF) las noticias, por el propio QDF, irán desbancándose unas a otras.
Por mucho que trabajemos un keyword research para cada una de las noticias la probabilidad de que muchas de ellas se formen desde la misma keyword («Juicio de los Ere«, «Caso Gurtel«, «Ascenso Cádiz CF«, «Golpe de Estado en Cataluña«) hacen ineficaz la granularidad de contenidos, donde solo una URL debe luchar por un grupo de palabras claves y no compartirlas con otras URLs.
El ejemplo al contrario podría ser un ecommerce que tuviera una sección para información sobre el aguacate, otra para la búsqueda transaccional comprar aguacate, otra sección para la búsqueda informacional recetas con aguacate, otra más para la receta de guacamole,… Todas estas estrategias de contenido que pueden funcionar en una web «normal», en el caso de los medios es algo que no tiene sentido porque no es posible hacer algo tan granular, como hemos dicho antes.
Las hemerotecas
Otro problema que se nos planteaba era el de las hemerotecas. En el caso de este medio la hemeroteca parte del año 2004, es decir, casi 14 años de contenidos. Durante el segundo año la web publicó la friolera cantidad de 993 artículos (friolera, bueno, el año pasado fueron 12.404 artículos).
Las hemerotecas de los medios de comunicación son fundamentales para poder estudiar lo que nos ha preocupado en los últimos tiempos y son muy interesantes para:
- Dotar de contexto a una noticia en particular
- Reforzar la estructura principal de la web.
Cuando publicamos algo que fué etiquetado con contenido similar reflotamos a solo dos clics de distancia de la home a una segunda noticia.
Tres clics de distancia de la home
Uno de los clásicos del mundo SEO es sacar a menos de tres clics de distancia de la home la mayoría de las secciones.
Pero el estado de una web de estas características hace que noticias antiguas queden bastante descolgadas.
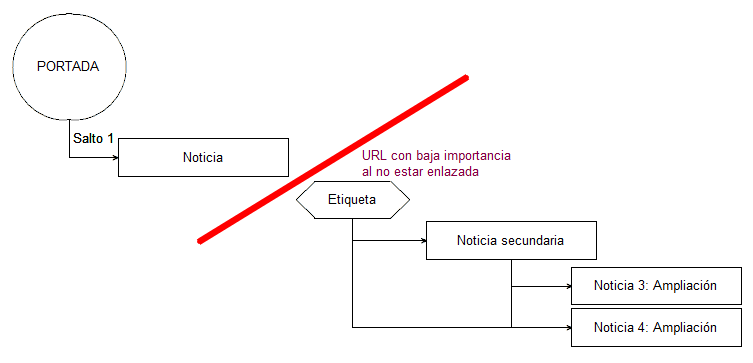
Mas saltos de los necesarios
En otro de los reportes de OnCrawl se ve que el bloque de noticias suele estar en una posición predominante a la hora de visibilidad. Casi el 59% de las noticias están a un solo clic de la home y, si vemos a menos de 3 clics de la home, el porcentaje sube a mas del 76%, lo cual tiene sentido si nos centramos en que, efectivamente, nos encontramos ante una web eminentemente de noticias.
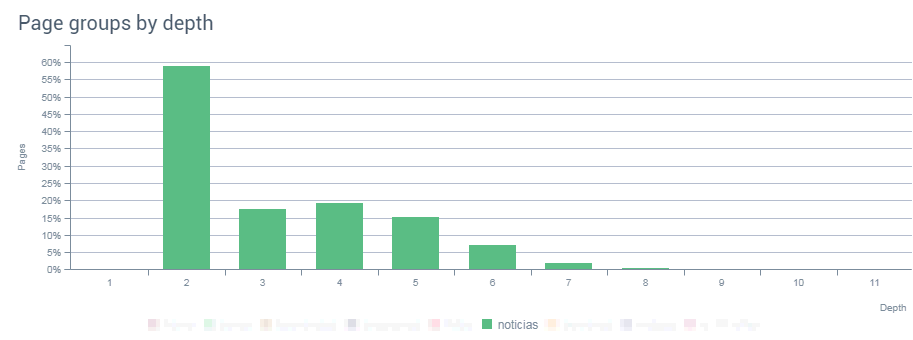
Grupo de páginas por profundidad
¿Qué quiere decir que más del 76% de las noticias estén a menos de tres clics de distancia de la home? Que la arquitectura de la web está trabajada para poder llegar a las noticias desde diferentes sitios (categorizaciones, posts, etiquetaciones, páginas intermedias, páginas de posicionamiento,…)
¿Cómo se consigue esto? Trabajando el etiquetado, las categorizaciones y los elementos intermedios. Estos elementos intermedios consiguen que el salto a noticias profundas se minimicen y se pueda llegar con relativa facilidad (cuatro clics de distancia de la home) a esas noticias profundas.
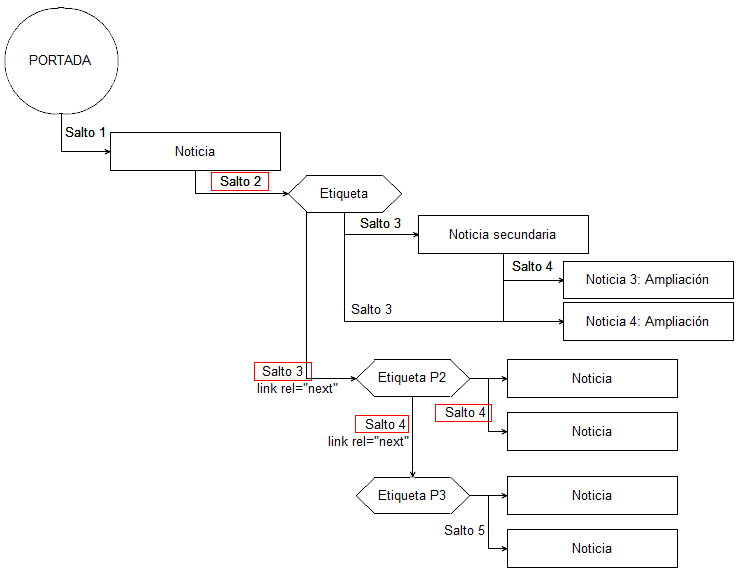
Etiquetas y categorías para minimizar el número de links de distancia de la home
Pero ¿Es esto la solución correcta? OnCrawl nos da una visión bastante general de la situación del bloque de noticias, algo que no responde a lo que estamos intentando averiguar y en nuestro favor llegan los Custom Fields, ya que estamos intentando averiguar cómo se comportan las visitas a las noticias, nuevas y antiguas.
Los custom fields de OnCrawl
Los custom fields se caracterizan por la capacidad de scrapear las webs en busca de elementos que puedan ser identificables y ordenables. El equipo de OnCrawl lo recomienda para:
- Reunir, por ejemplo, los precios de un producto o una determinada sección de una página.
- Recoger el número de comentarios en un artículo o el número de anuncios y formatos de una página.
- Si tienes el tag de analytics en todas las URLs de tu web.
- Listar qué productos similares está sacando la web.
La verdad es que hay muchas posibilidades más y creo que tenemos una de las mas interesantes: Conseguir sacar, vía custom fields, las fechas de las noticias.
Custom fields: scraping de schema
Para crear los segmentos que necesitamos usaremos el código schema Article, que la web ya tiene implementado y usaremos el campo date published.
<script type="application/ld+json">{
"@context": "http://schema.org/article",
"@type": "Article",
"author": "John Smith",
"datePublished": "2009-05-08",}
</script>
Los segmentos que crearemos son aquellos via Regex, donde capturaremos toda la fecha : "datePublished" : "([^"]*)" bajo el año que nos interese. Como vemos, la estructura es "datePublished": "2009-05-08"por lo que tendremos que extraer es "datePublished": "2009-*" para captar los datos.
Paso 1: Preparar un nuevo crawl con los datos que queremos exportar, habilitando el scraping
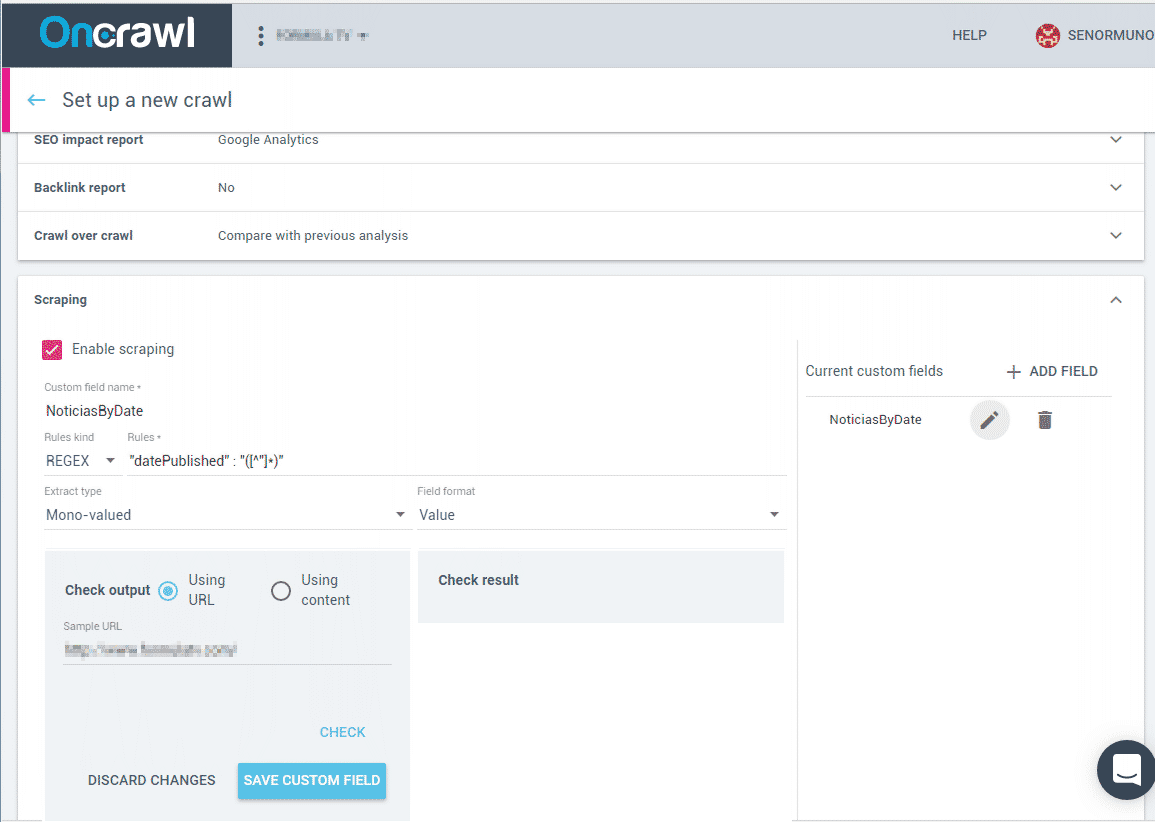
Preparación OnCrawl lanzamiento de crawl con custom-fields
Paso 2: Configurar segmentación.
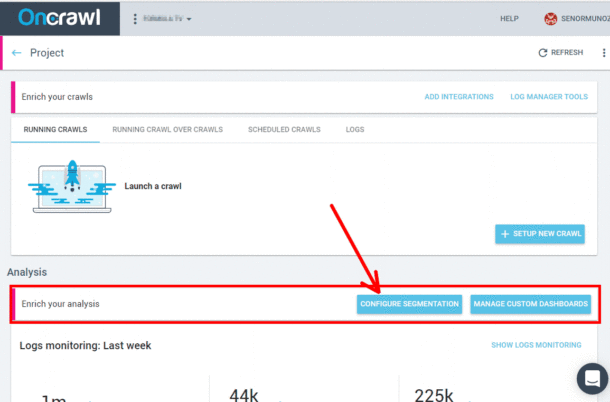
Custom fields OnCrawl
Paso 3: Crear nuevo segmento
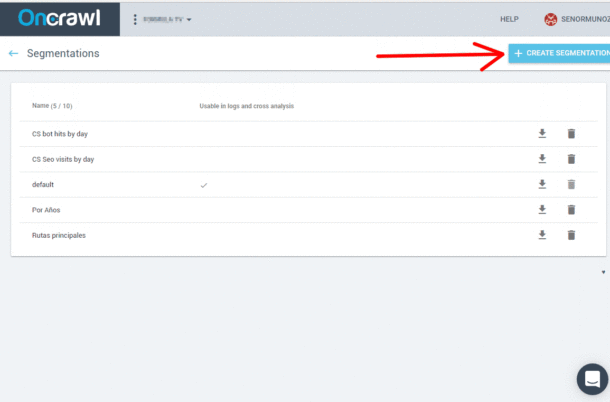
Crear segmentación OnCrawl: Custom Fields
Paso 4: Nombrarlo, marcarlo como JSON y establecer el código del scraping.
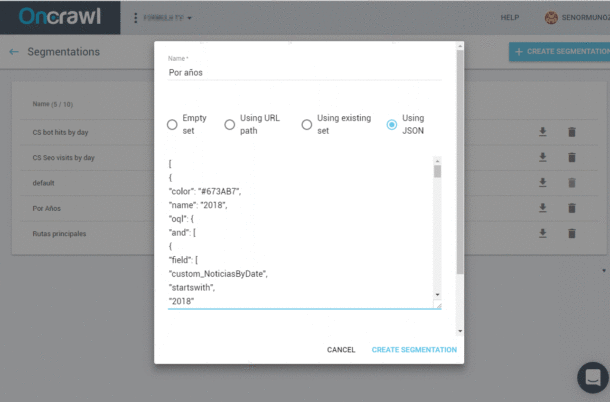
Crear segmentación onCrawl: Custom Fields
[
{
"color": "#673AB7",
"name": "2018",
"oql": {
"and": [
{"field": ["custom_NoticiasByDate","startswith","2018"]}
]
}
},
{
repetir tantas veces como sea necesario
},
]
Con lo que tendremos una pantalla parecida a esta:
Crear segmentación OnCrawl: Custom Fields para exportar json por años
A partir de este momento ya tenemos nuestro bloque de noticias segmentados por años ¡No me digáis que no es sencillo!
Vale, ¿ahora qué hago?
Ahora vamos a aprovechar el crawleo y la incorporación de los logs de servidor. Recordad que vamos buscando poder identificar qué hacemos con las noticias, las nuevas y las antiguas.
En esta tabla podemos ver de qué estamos hablando y qué estamos intentando identificar. Como veis, hacemos una segmentación por número de hits de Google y numero de visitas SEO. No hace falta ser un hacha para darse cuenta que las noticias del 2011 en adelante no cuentan con muchas visitas. Pero la clave está en la comparativa que Sergio hace: el numero de hits de Google vs el numero de visitas SEO.
Hay mucha menos proporción de hits/SEO en las noticias del 2017 y del 2018 que, por ejemplo, del 2014 al 2008. Tiene sentido, porque son las noticias que más visitas tienen, las que más visitas SEO se llevan actualmente. Un total de 46821 URLs de noticias, un 60% de las URLs de noticias, que, además, suponen un poco más de 186.000 visitas, o, lo que es lo mismo, un poco más del 2% de las visitas son la clave para decidir qué hacemos con la hemeroteca. Si seguimos escudriñando resulta que por el 2% de las visitas de usuarios reales, ese mismo bloque de noticias se lleva más del 31% de los hits de Google.
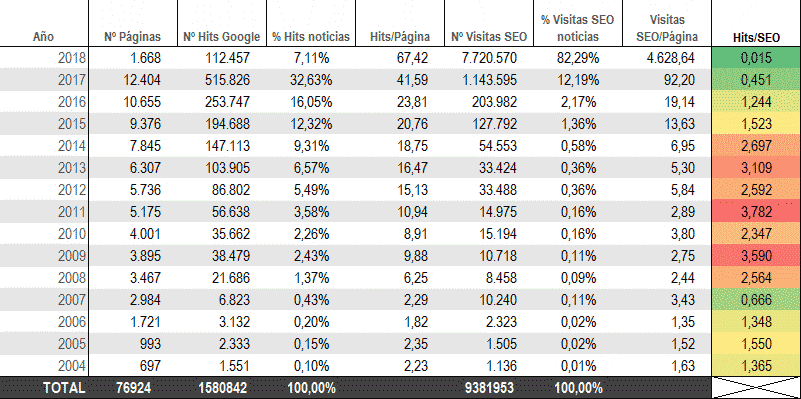
Noticias por años. Crawling y visitas.
Glosario:
- Nº de páginas (Número de páginas que OnCrawl + logs han identificado.
- Nº hits de Google: Número de visitas que Google ha realizado a las páginas de noticias
- % hits noticias: Porcentaje de hits según el número de páginas.
- Hits por página: Número medio de hits por cada página.
- Nº visitas SEO: Pues eso 😀
- % visitas SEO noticias: Porcentaje de visitas, desde el punto de vista SEO, a las noticias del año en cuestión.
- Visitas SEO/página: Número de visitas por página.
- Hits / SEO: Hits de Google por cada visita SEO.
Entonces ¿Qué hacemos?
Vale, tío, no me ralles más ¿Qué vas a hacer?
Sinceramente: no tengo ni idea. Creo que voy a arreglar otras cosas antes que esto. Pero yo veo 2 opciones para la parte de las noticias antiguas y la hemeroteca:
- El cuerpo me pide bloquear y desindexar la hemeroteca. Ese 2% de visitas creo que es menos interesante que la mejora que podemos darle a google rastreando correctamente las URLs que más nos interesan.
- Bloquear las paginaciones de las noticias (y sus agregadas etiquetas, categorizaciones,…) para evitar pasar relevancia a noticias antiguas. Si Google no es capaz de encontrarla en la navegación debería tener impacto sobre el número de hits/SEO del proyecto?
Pues hasta aquí el teaser, si quieres más, solo tienes que venir al Congreso SEO Profesional o pedir una demo de onCrawl para intentar sacar tus propios datos.
Y podemos discutir en los comentarios ¿Tú que harías con estos datos?
Fotografía de portada: https://gratisography.com/
Deja una respuesta