Las compliant pages de OnCrawl son aquellas páginas HTML de un sitio web que son susceptibles ser indexadas y rankeadas por Google:
- páginas que el robots.txt no bloquea
- páginas que no tienen noindex en sus <meta name=»robots»>
- páginas que dan 200
- páginas que no hacen redirecciones 30x
- páginas que no dan errores 4xx
- páginas que no dan errores 5xx
- páginas cuyo canonical se apuntan a sí mismas.
¿Qué no son compliant pages en OnCrawl?
- Aquellas URLs que no son HTML (jpg, pdf,…)
- Aquellas que dan errores (30x, 40x, 50x)
- Aquellas cuyo canonical apuntan a otro sitio que no son ellas mismas.
Ejemplos de compliant page o no compliant pages «extravagantes»
- Si
- Una paginación SI es una compliant page si el canonical está bien puesto (es decir, sí si se apunta a sí misma como fuente principal del contenido o no si apunta a otra URL como fuente principal)
- No
- Una paginación con un canonical a otra URL (por ejemplo, los filtros) no es compliant page.
- Una página que apunta con un canonical a otra NO es compliant.
- Una página de una versión móvil (m.dominio/url) NO es compliant porque debe llevar un canonical a la URL desktop (al menos de momento).
- Una página de una versióm amp (dominio/amp/url o amp.dominio/url) NO es una compliant porque debe llevar un canonical a la versión desktop.
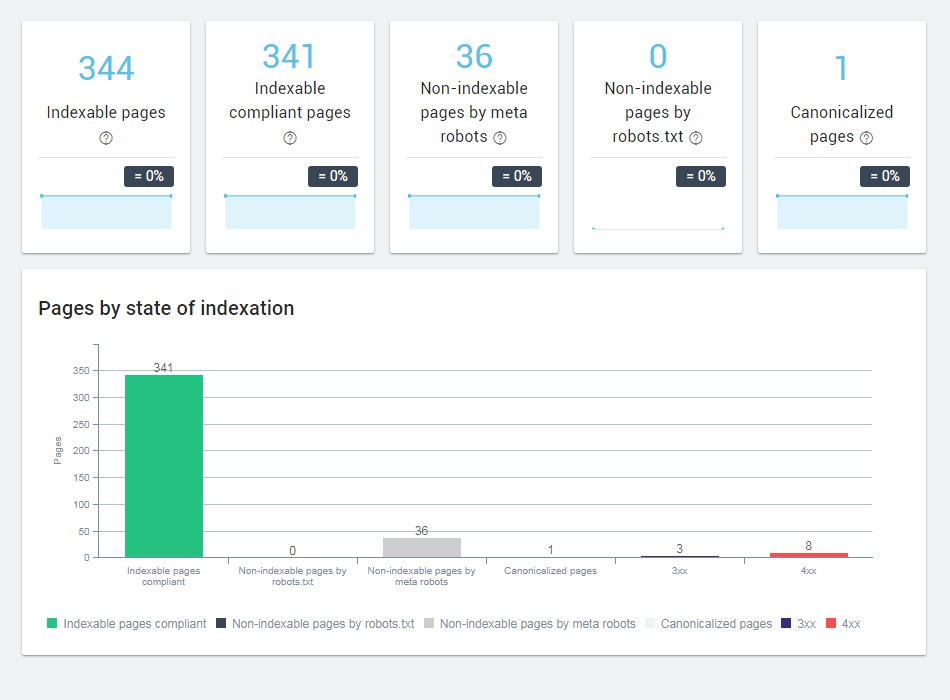
Cuadro de mando de OnCrawl: Compliant page, non-indexable,…
Explicación del cuadro de mandos
Primera línea
- Indexable pages: Páginas que son indexables a buscadores y captadas por OnCrawl. No tienen metaetiqueta noindex y no están bloqueadas por robots.txt. El contenido de esas páginas ha sido analizado.
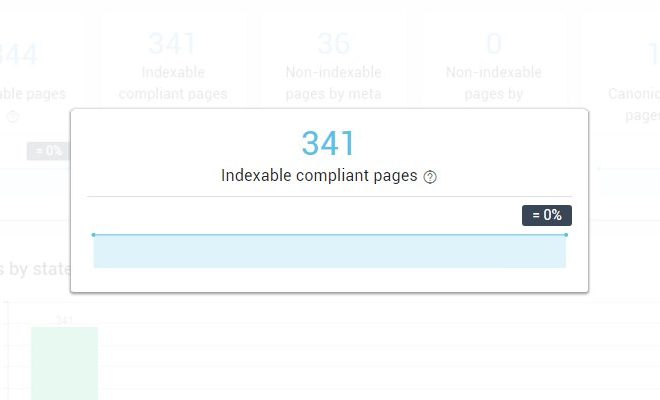
- Indexable compliant pages: Páginas captadas por OnCrawl sin noindex y un status code válido (200). El contenido de esas páginas ha sido analizado.
- Non-indexable pages by meta robots: Páginas que tienen un <meta name=»robots»> con noindex. El contenido NO ha sido analizado.
- Non-idexable pages by robots.txt: Páginas que no han sido captadas por OnCrawl porque se lo ha impedido el robots.txt
- Canonicalized pages: Páginas que tienen un canonical hacia otra URL
Segunda línea
- Indexable pages compliant: Páginas válidas y susceptibles de rankear.
- Non-indexable pages by robots.txt: Páginas bloquedas por el robots.txt. No indexables.
- Non-indexable pages by meta robots: Páginas bloqueadas por el <meta name=»robots»>
- Canonicalized pages: Páginas canonicalizadas a otras URLs.
- 3xx: Páginas con errores 3xx
- 4xx: Páginas con errores 4xx.
¿Por qué son relevantes las compliant pages?
Porque tenemos que evitar a google cualquier error: ya sean redirecciones 301 (movido permanentemente), 302 (encontrado, pero movido temporalmente), 307 (redireccionado temporal), 303 (ver otro), ya sean errores 400 (petición errónea) 404 (página no encontrada), 403 (página prohibida) o 410 (página eliminada definitivamente) o ya sean errores 50x. Cuanto más sano esté nuestro sitio web, mejor.
Compliant pages por categorías
Si tenemos nuestras categorías bien definidas podemos saber qué tipologías de páginas presentan una mejor salud.
¿Qué hacer con las URLs que no sean compliant page?
Esta creo que es la pregunta del millón. Pero el problema es que me temo que no existe una única respuesta. Por defecto yo haría lo siguiente con aquellas páginas marcadas como «no compliant»:
- Si son HTML
- Ver si son susceptibles de ser indexadas.
- Si lo son, hay que solucionar el 40x, 50x, 30x o el canonical que se lo impide.
- Si no lo son, ver si hay que eliminar esa URL o bloquearla.
- Ver si son susceptibles de ser indexadas.
- Si son PDF:
- Nada si son PDFs interesantes
- Si existe una URL para el PDF, marcar al PDF como canonical y si esto no es posible, marcarlo como noindexable.
- Si son versiones móviles o amp
- Nada, son páginas importantes pero es la forma en la que OnCrawl mide y hasta que cambie, poco se puede hacer.
Deja una respuesta