¿Cuando usar el canonical y el noindex? ¿Es bueno que estén juntos? ¿Es malo? Bueno, te damos nuestra opinión y te mostramos nuestras pruebas para que tu decidas ¿No tienes ganas de leer las pruebas? Ok, click aquí si eres TL;DR.
Las directivas canonicals y noindex
En Señor Muñoz llevamos desde hace un tiempo realizando una serie de tests para ver si realmente Google interpreta ciertas directivas tal y como dice que lo hace. Para ello, la primera directiva en la que pusimos el ojo fue la directiva canonical.
Canonical
Veamos primero lo que dice Google sobre la etiqueta rel=canonical.
En 2009, Google anunciaba el soporte de la etiqueta rel=canonical, destinada a solucionar los problemas de contenido duplicado, ya que permitía relacionar las páginas que eran versiones duplicadas con su versión original o canónica. En el post donde se hace este anuncio se puede leer lo siguiente:
¿Es el rel=»canonical» una recomendación o una directiva?
Es una recomendación que apoyamos firmemente. Tomamos en cuenta tu preferencia junto con otras señales cuando calculamos la páginas más relevantes que se muestran en los resultados de búsqueda.
Es decir, Google afirma que aunque considera esta etiqueta una señal muy fuerte y la apoya bastante, no siempre tiene porqué seguir su indicación.
De hecho, en un artículo publicado en 2013 en el mismo blog, Google dice lo siguiente (negritas nuestras):
Implementando el elemento con el atributo rel = canonical en tu sitio web proporciona una fuerte señal a los motores de búsqueda para indicar cual es la versión preferida para ser indexada entre varias páginas duplicadas en tu sitio web. […] El elemento con el atributo rel = canonical consolida propiedades de indexación de los elementos duplicados, como tus enlaces entrantes, así como especifica la URL preferida en los resultados de búsqueda.
De nuevo viene a incidir en la fuerza de la etiqueta rel=canonical a la hora de indicar a los motores de búsqueda cómo interpretar el contenido duplicado marcado con dicha etiqueta, pero en ningún momento afirma que su cumplimiento sea obligatorio.
El que nos planteásemos este test vino por la experiencia de haber comprobado cómo en, según qué ocasiones, Google efectivamente respetaba esta directiva para unos casos y la pasaba por alto para otros.
Los experimentos y por qué comprobarlos con el noindex
En varias ocasiones nos hemos encontrado con la recomendación por parte de Google de no poner la etiqueta rel=»canonical» en aquellas páginas que además estén marcadas como noindex.
Sin embargo, podemos encontrar multitud de páginas marcadas como noindex que presentan el canonical apuntando a sí mismas.
En un hangout de Webmasters de Google tuvimos la oportunidad de preguntar directamente a John Mueller sobre el tema y su respuesta fue precisamente esa misma recomendación, lo mismo que en su día ya recomendó también Matt Cutts.
En principio tiene lógica: si una página no queremos que se indexe, para lo cual añadimos un meta robots noindex, no tiene sentido que por otro indiquemos a Google que considere esa página como canónica para ningún caso.
A partir de esto, quisimos comprobar de qué manera se comporta Google ante una página que presenta tanto un canonical apuntando a sí misma como una etiqueta meta robots noindex. Para ello hicimos dos tests distintos:
- en el primer test, a unas landings que hacían canonical a sí mismas y que estaban indexadas en Google les añadimos la etiqueta meta robots con noindex.
- En el segundo, creamos las landings directamente con ambas etiquetas antes de ponerlas online.
A continuación desarrollamos un poco más cada uno de los experimentos.
Experimento 1: landings con canonicals a si mismos y ya indexadas a las que le añadíamos noindex
Metodología y desarrollo del experimento
Creamos cuatro URLs distintas, cada una luchando por keywords distintas. A todas ellas les añadimos la etiqueta rel canonical apuntando a sí mismas y dejamos que Google las indexara.
Una vez nos aseguramos que las cuatro URLs estaban indexadas, procedimos a añadirle la etiqueta meta robots noindex, en dos de ellas después del canonical, y en las otras dos antes. Una vez hecho esto pasamos las cuatro URLs por ‘Explorar como Google’ de Search Console. Desde entonces hasta ahora, las cuatro URLs continúan indexadas.
Primer paso:
| URL | 1º |
| URL A | canonical a sí misma |
| URL B | canonical a sí misma |
| URL C | canonical a sí misma |
| URL D | canonical a sí misma |
Segundo paso: tras primera indexación
| URL | 1º | 2º |
| URL A | canonical a sí misma | meta robot noindex, nofollow |
| URL B | canonical a sí misma | meta robots noindex, follow |
| URL C | meta robot noindex, nofollow | canonical a sí misma |
| URL D | meta robots noindex, follow | canonical a sí misma |
Experimento 2: landings directamente con ambas etiquetas antes de ponerlas online
En este caso creamos también otras 4 URLs, solo que esta vez les añadimos directamente tanto el canonical como el noindex, cambiando el orden de las mismas de modo que en dos de ellas apareciera antes el canonical y en las otras dos el noindex. Desde entonces hasta ahora, ninguna de ellas se ha indexado.
| URL | 1º | 2º |
| URL E | canonical a sí misma | meta robot noindex, nofollow |
| URL F | canonical a sí misma | meta robots noindex, follow |
| URL G | meta robot noindex, nofollow | canonical a sí misma |
| URL H | meta robots noindex, follow | canonical a sí misma |
Resumiendo:
Como podemos ver por los dos experimentos realizados, las URLs que inicialmente hacían canonical a sí mismas y a las que posteriormente se les añadió un noindex continúan indexadas (Es decir, Google no ha respetado la etiqueta meta robots). Sin embargo, aquellas URLs a las que se se les ha puesto desde un principio tanto el canonical a sí mismas como el noindex, no se han indexado en ningún momento (es decir, Google ha respetado el meta robots):
| URL | Índice de Google |
| URL A | indexada |
| URL B | indexada |
| URL C | indexada |
| URL D | indexada |
| URL E | no indexada |
| URL F | no indexada |
| URL G | no indexada |
| URL H | no indexada |
- Si una URL, al ser rastreada por primera vez, presenta las etiquetas canonical y noindex, Google respeta el noindex.
- Si una URL, al ser rastreada por primera vez, presenta el canonical, y posteriormente se le añade el noindex, Google mantiene la URL indexada a pesar del noindex. En las URLs de nuestro experimento, si accedemos a la caché de Google, podemos ver que en el código fuente presenta el noindex (ocultamos los datos para evitar que nadie desvirtue el experimento enlazando a la landing de ejemplo)
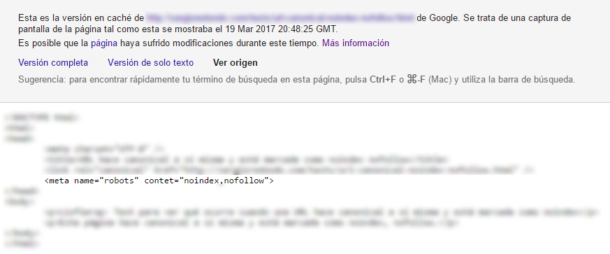
Canonicals y no index
Conclusión:
Dependiendo del momento en que combinemos canonical y noindex, Google respetará una u otra, por lo que si queremos asegurarnos de que Google desindexe una URL que ya teníamos indexada, lo mejor es quitarle el canonical (si lo tiene) y marcarla con noindex.
Muy bueno el artículo y el experimento, saludos!!
Buen experimento!!
A mi me han pasado cosas similares tb..
Gracias por compartirlo con todoss 😉
¿Podría ser que en el segundo experimento (crearlas nuevas ya con meta noindex) no las indexe no por el meta, sino porque no tienen enlaces entrantes?
Estaría bien que ahora publicases esas que no se indexan y a ver qué ocurre cuando se las enlaza.
Hola, yo no creo que se pueda afirmar aun lo que planteas con tanta seguridad con solo ese experimento . Habría que comparar el primer experimento con otras cuatro URL que han indexado igual y que le añades el noindex sin el rel canonical. La mayoría de las veces Google tiene que crawlear muchas veces para desindexar una url. Lo que puede pasar también es que al ver el noindex se crawlee menos y necesites subir un sitemap a search console con esas url
Gracias a todos por los comentarios.
Lino, todas las URLs están enlazadas.
José María, en cuanto a lo que comentas de probar a subir otras 4 URLs sin canonical y posteriormente añadirle noindex, sin duda es un test que podríamos haber hecho, pero la experiencia me dice que en ese caso las URLS de desindexarían rápidamente. De todos modos, me lo apunto.
En cuanto a lo que comentas de que Google tiene que crawlear varias veces una URL para desindexarla, insisto, la experiencia me dice que si la URL solo tiene el noindex la desindexación es relativamente rápida. Lo que pretendo plantear en el post es la problemática del uso conjunto de canonical y noindex: no pretendo decir que si el noindex se añade posteriormente al canonical la URL no se vaya a desindexar, sino que la desindexación no se realiza con rapidez, cosa que me parece importante teniendo en cuenta que el canonical no es de obligado cumplimiento mientras que el meta robots sí.
Hola nuevamente Sergio,
Ahora con los datos que añades en tu último comentario, que por tu experiencia vivida, las paginas en las que metes un meta robots=»noindex» y no llevan canonical desindexan más rápido, sí podría tener más sentido tu afirmación. Eso no lo discuto porque no me he fijado nunca en eso para compararlo 😀 Sin embargo, espero que entiendas que solo con el experimento publicado en el post, y sin ese dato extra que estás aportando ahora, pudiera cuestionarse por falta de más datos para comparar…
Aún así, sigo pensando que para dejar el post redondo, faltarían ese extra de otras 4 url sin el canonical. Entonces sí se podría afirmar con total rotundidad. 😀
En todo caso, se agradece mucho tu aporte porque me ha dado para pensar e intentar entender un poco mejor como actúa el algoritmo de Google a la hora de rastrear las páginas 😉 Asumiendo que es así lo que planteas, podría ser debido a la granularidad de Google. Me explico:
De la misma manera que el proceso de crawleo y el de indexación son dos procesos distintos, y a la vista está, ya que muchas paginas bloqueadas en robots.txt con un meta noindex indexan porque Google no entra a la misma para ver el código fuente con la directiva noindex; es posible que con los canonical suceda algo parecido con cierta relación. En este caso, lo que pienso es que Google ve la directiva noindex, pero por otro lado, con el canonical lo mande también a la cola de otro proceso parecido o relacionado con la indexación. Al final tiene como una especie de «conflicto» y lo hace demorar más tiempo 😀
Es una hipotesis que planteo, igual se me ha ido la pinza un poco jeje
Muchísimas gracias por tu comentario, José María. Me parece un aporte de mucho valor.
Efectivamente, has dado con la palabra: conflicto. De hecho, a ver si encuentro por ahí un hangout en el que John Mueller habla precisamente de conflicto entre ambas etiquetas.
Gracias de nuevo.
Interesante, muy interesante. Sin embargo: ¿Sergio rankeaban peor? No sé si esto lo pudistéis medir (o no).
En un proyecto, donde me está pasando de todo, he observado que sí. Recientemente, debido al típico módulo kamikaze disfrazado como beneficios para SEO y con el logo de un panda en una jaula, descubrí que se estaba añadiendo la directiva no-index a productos agotados temporalmente (vamos si quantity no index por la cara).
Por suerte, no se desindexaron las fichas de producto pero cayeron +40 aproximadamente. Al descubrir el problema y solventarlo han recuperando su posición original.
Muchas gracias por tu comentario, Rubén.
La verdad es que no es algo que hayamos podido medir, ya que en los tests utilizamos keywords para las que sabemos que no vamos a tener búsquedas ni competencia.
Ten en cuenta que los tests los hacemos para comprobar única y exclusivamente aquello que queremos comprobar, nada más.
Gracias de nuevo.
Hola Sergio, este post me lo leí hace ya bastantes meses y justo hoy me ha surgido un conflicto precisamente con lo que comentas en él.
Te comento, yo gestiono el SEO de un ecommerce donde existen gran cantidad de productos sin stock que no se pueden eliminar. Todos estos productos en su momento estaban indexados y atraían algo de tráfico pero con un rebote del 95%. La solución que tomamos fue, como mencionas en el post, añadirles un Noindex y quitarles el canonical. Pasado un tiempo todos esos productos se desindexaron y el rebote general de la web bajó del 30% al 20% en prácticamente una semana (y sin pérdida de tráfico).
Hoy, tras meses de implementar ese cambio (que ha sido muy positivo) me ha dado por mirar el índice de indexación del nuevo search console y para mi sorpresa tenía unos 300 errores por «URLs duplicadas sin canonical». Al revisarlo veo que proviene de esas urls de producto sin stock y esa supuesta duplicidad la genera con esas mismas urls con UTMs. Es decir, en su momento se usaron UTMs para esos productos que como tenían el canonical no había problema. Al quitar el canonical a ojos de google (y aunque no estén indexadas) tienes dos urls duplicadas sin canonical.
Cuestión, que si le dejas el canonical-noindex no se desindexa, pero si se lo quitas y esa url puede tener algún parámetro te salta el aviso de contenido duplicado. Si que es cierto que ahora que está desindexada podría añadirle de nuevo el canonical y listo, pero de cara a gestionar miles de productos no es muy viable.
¿Crees que existiría alguna solución a este tema? ¿o lo dejarías tal cual está aunque hayan avisos de esas URLs duplicadas? Un saludo!
Muchas gracias por compartir tu experiencia, Iván.
Posiblemente no lo dejé claro en el post (aunque sí lo tienes en la respuesta al comentario de José María: http://www.senormunoz.es/SEO-MARBELLA/canonicals-y-noindex-mejor-juntos-o-por-separado#comment-162593), pero no pretendo afirmar que si usamos canonical+noindex la URL no se desindexa, sino que tarda más.
En cuanto a tu caso, claro, entiendo que el problema lo tienes porque pusiste como noindex las URLs de los productos pero no así sus variantes con UTM. ¿Te has planteado controlar la indexación de esos parámetros en Search Console?
Espectacular Sergio. Muy interesante y con este problema creo que me encuentro yo.
Me he dado cuenta de que en mis páginas de listados de productos con filtros aplicados tengo noindex,follow (porque está filtrado y no quiero dar relevancia) pero tengo un canonical a si mismo. Google debe flipar conmigo. Estas URL serían de tu experimento el caso 1: antes tenían canonical y no tenían el noindex pero ahora sí tienen el noindex y mantengo el canonical.
Creo que es hora de cambiar eso. ¿Qué es mejor?
– noindex,follow sin canonical
– index,follow con canonical a la url de listado de productos pero sin filtros?
Esto sería:
url: http://www.example.com/lista-productos/orden-precio-menor/
robots: index,follow (all)
canonical: http://www.example.com/lista-productos/
Un saludo y gracias!
Hola a todos, creo que llegué un poco a destiempo. De cualquier manera hago la pregunta a ver si por aquí alguien tiene la respuesta.
Este caso del post expone cuando una canónical apunta a si misma, pero cuando la canónical apunta a otra URL el noindex es válido, ¿cierto?
Si lleva canonical, no lleva noindex. Si lleva noindex, no lleva canonical.