
El canonical es una directiva máquina, trabajada como etiqueta <meta>, que se coloca en el campo <head>, apoyada por bing!, Google y Yahoo e ideada para trabajar el contenido duplicado, indicando en ella cuál es el contenido original. Nacida en el 2009 en pleno auge de la sindicación de contenidos, es una forma de ayudar a los buscadores a elegir cuál es el contenido original y permitirles identificar correctamente el emisor original de este.
El canonical y otras etiquetas
- Canonical con rel=prev y rel=next
- Canonical con hreflang
- Canonical con hreflang y xdefault
- Canonical con amp
- Canonical con versión móvil
- Canonical con noindex
- Canonical con robots.txt
El canonical es una directiva de aconsejable cumplimiento, pero no es de obligado cumplimiento, porque ya han avisado más de una vez que si las señales son claras en otro sentido, mostrarán como contenido principal una URL aunque esta tenga el canonical a otra a su vez… Si necesitas más información, aquí podeis encontrarla.

En general, se recomienda el uso del rel canonical ante los siguientes escenarios:
- Ante diferentes URLs (sobre todo aquellas que están identificadas con parámetros) decirle a la máquina cuál es la original.
- Ante una sindicación de contenidos, definir cuál es el dominio emisor del contenido.
- Ante una coexistencia de protocolos diferentes (http, https) o errores en la construcción del dominio (www. y sin www) o ante dominios diferentes (senormunoz.es y senormunoz.com, ambos abiertos a indexación y ambos con el mismo contenido)
En este artículo os mostraremos diferentes posibilidades para permitir la coexistencia, o no, de una meta etiqueta rel canonical con otras meta etiquetas como son la rel=prev y rel=next, rel=noindex, amphtml, alternate móvil,…
canonical amp alternate rel prev rel next xreflang hreflang
1. Canonical con rel=prev y rel=next
1.1. rel=prev y rel=next
La directiva rel=prev y rel=next es la forma de indicar al buscador que estamos ante una paginación de contenidos. Es decir: el contenido se dispersa en diversas URLs que tienen un orden específico. El beneficio reside en indicarle al buscador cómo debe gestionar el contenido de una página. Tiene dos escenarios:
- una paginación sin URL que tenga todos los contenidos agregados
- una paginación con URL que tenga todos los contenidos agregados.
1.2. rel=prev, rel=next y canonical
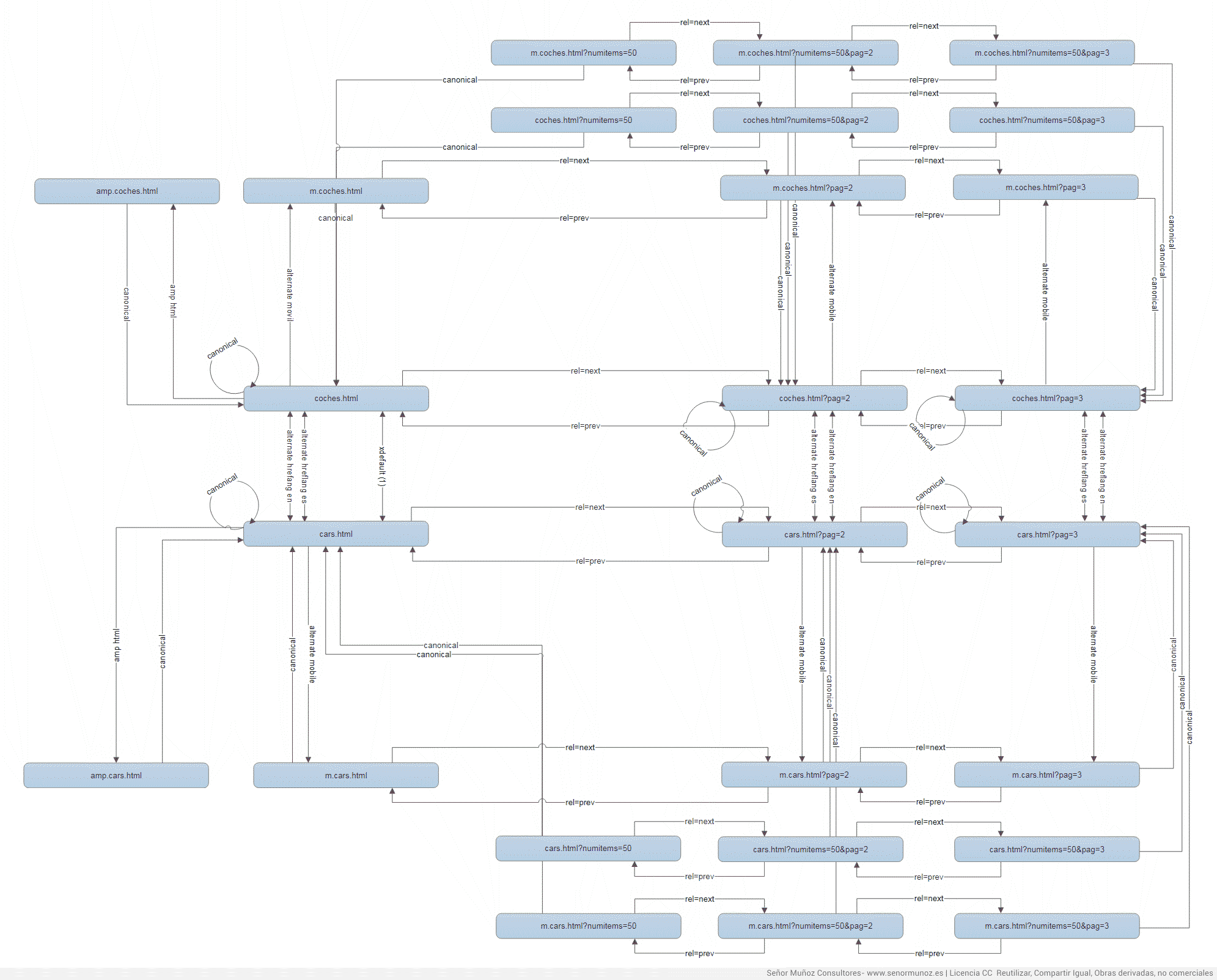
1) Si tenemos una paginación sin URL agregadora, solo llevará el rel=prev y el rel=next. No tiene por qué llevar rel=canonical.

rel=canonical con paginación, rel=prev y rel=next
2) El canonical podemos utilizarlo conjuntamente con rel=prev y rel=next cuando necesitemos establecer la versión canónica de las paginaciones, por ejemplo, cuando encontremos parámetros en estas URLs.

rel=canonical con paginación rel=prev y rel=next y el canonical a sí misma.
Si bien esta opción no es relevante o no está aconsejada de modo expreso en las guidelines, tampoco está contraindicado, por lo que puedes ponerlo o no.
3) El canonical y la paginación cruzada entre páginas y listados consecutivos debemos apuntar las canonicals desde las URLs con parámetros y paginación a la URL sin parámetros no paginados
Paginaciones y canónicasl con parámetros
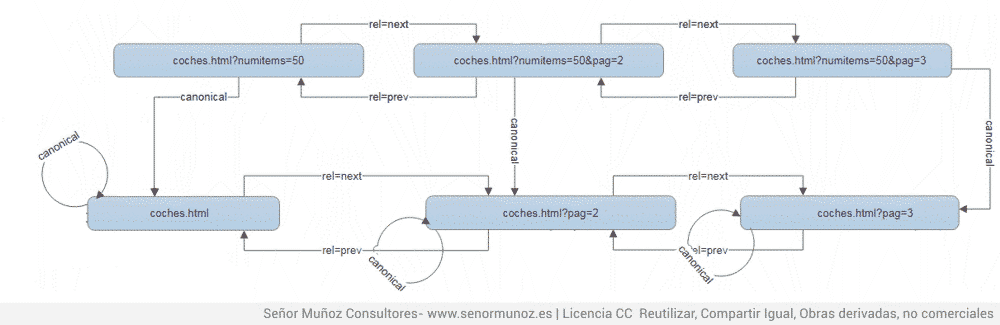
4) Sin embargo la siguiente es mucho más normal, donde la paginación con parámetros (en este caso, un parámetro como es numitems, que no requiere de posicionamiento) a la URL sin más parámetros que la mera paginación. Si tenemos una paginación con URL agregadora, las distintas paginaciones deberán incluir el rel=canonical a la versión agregadora
rel= canonical con paginación rel=prev y rel=next y URL que unifica todo el contenido.
2. Canonical con hreflang
Quizá una de las partes más complicadas, ya que es interesante ver cómo el canonical y el hreflang, pudiendo coincidir, realmente no trabajan juntos. Ya sabemos que el canonical se inventó para intentar luchar contra los contenidos duplicados, pero veamos antes qué es el hreflang.
2.1. hreflang
El hreflang es la forma de indicar al buscador que dos páginas son iguales pero enfocadas a 1) países diferentes 2) idiomas diferentes 3) países e idiomas diferentes. Se basa en el ISO 639-1 El beneficio es claro: puedes orientar a diferentes mercados con el mismo idioma. El hreflang lo que busca es ayudar a determinar qué URL ranquea por una palabra en un determinado idioma o país o país e idioma. El hreflang tiene dos consideraciones :
- debe tener URL de vuelta (es decir, si url-idioma1.htm apunta a url-idioma2.htm, desde url-idioma2.htm también debe apuntar a url-idioma1.htm
- debe apuntarse a sí mismo (url-idioma1.htm se apuntará con el hreflang correspondiente a url-idioma1.htm)
2.2. hreflang y canonical
- puede no existir el canonical
- si existe el canonical debe coincidir con el hreflang de la versión en la que estemos.
- si hay una copia no lleva hreflang, pero si canonical a la versión original.
- si hay un parámetro que 1) debe ordenar el contenido (ejemplo: parámetro de ordenación) o 2) no varía el contenido (ejemplo: id de sesión) y, además, 3) no es necesario para nuestra indexación porque no nos interesa indexar esa URL (ejemplo: en la URL de coches mostrar solamente los SEAT podríamos querer indexar esa URL para posicionar por «coches SEAT») no lleva hreflang, pero si canonical a la URL sin parámetros.
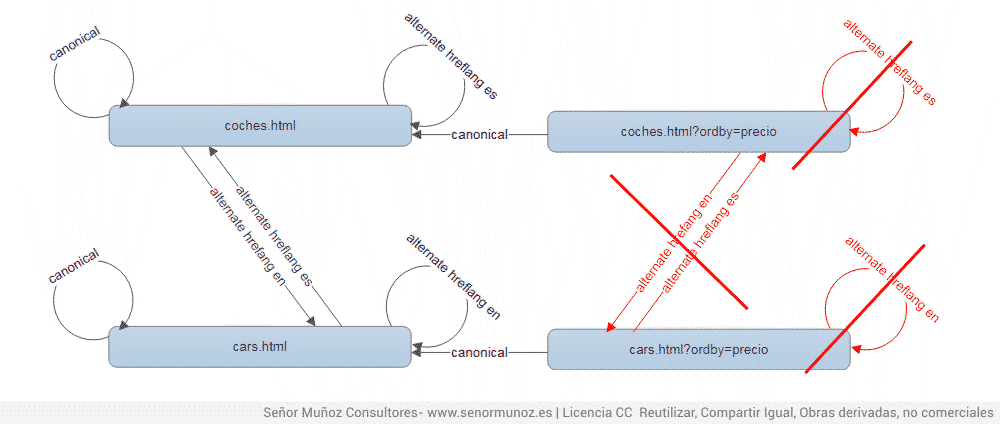
rel=alternate hreflang de idioma y rel=canonical
3. Canonical con hreflang y xdefault
3.1. x-default
El parámetro x-default va en unión con el hreflang (no puede ir solo) y sirve para indicarle a google dónde nos gustaría que fuera un usuario que no está representado por ninguna de las URLs idiomáticas/paises/ambas. Al principio lo mandábamos a una URL de desambiguación pero con el tiempo se ha aceptado también su uso para decirle al buscador: «ey, no tengo para esa combinación, así que muéstrale esta url».
3.2. x-default y canonical
Como hemos dicho antes, siempre debe coincidir la URL canonical con una de las URLs de hreflang (y lo comentó John Mueller en este post de Google +). En este ejemplo el canonical se apunta a sí mismo en cada una de las versiones, ya que la versión UK y US son dos URLs con contenido trabajado para cada uno de los países marcados y su respectivo idioma (en-UK y en-US).
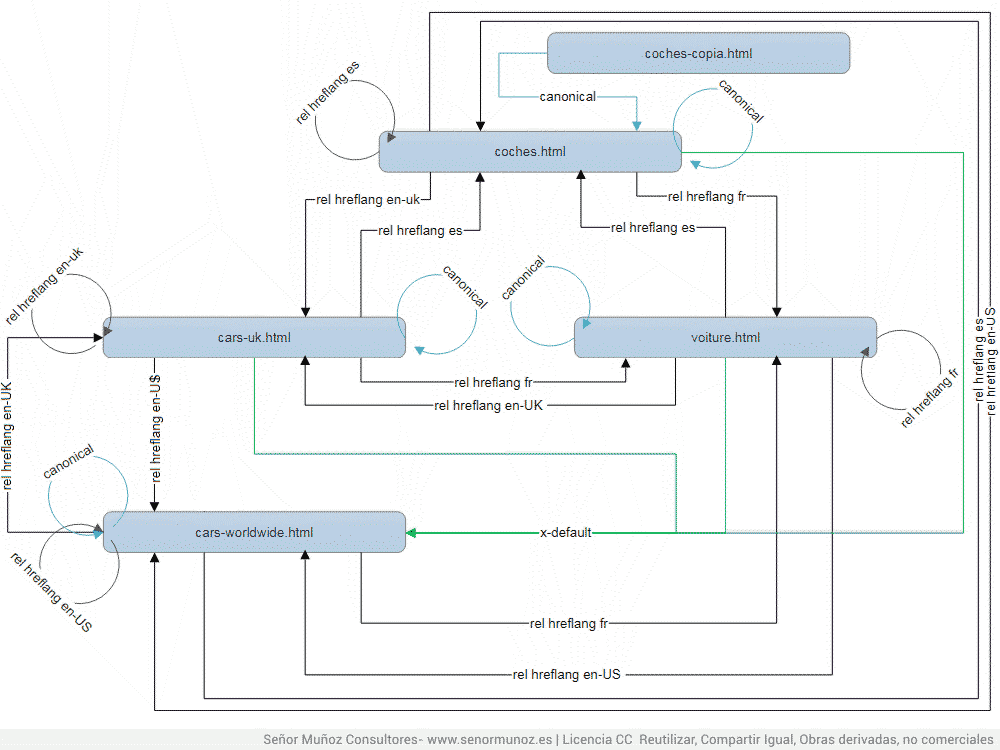
rel=alternate hreflang x-default y canonical
3.3. hreflang, canonical y la sindicación de contenidos en el mismo idioma entre portales
Sin embargo hay un caso en el que el obvio uso del canonical no es cómo se espera. Esto (os cuento un secreto, ha costado varios días de discusión entre Sergio Redondo, un servidor y con la ayuda especial de Gianluca Fiorelli, Fernando Maciá, Aleyda Solis, David Campañó, Carlos Estevez, Iñaki Huerta y David Martín, a los que doy las gracias por aguantarme y hacerme recapacitar)
Antes, un video de distilled hablando del tema
Como íbamos diciendo, estamos en una situación especial, donde tenemos que dilucidar qué hacemos en el caso que sean copias de contenidos en el mismo idioma. Imaginemos una situación tal que la siguiente: el contenido original lo produce una web en España, que se copia, exactamente, en las webs de Perú, México y Argentina (es indiferente si es un dominio con subcarpetas idiomáticas, un dominio con subdominios idiomáticos o diferentes dominios para cada uno de los países). Se ha decidido, además, que la web con el dominio terminado en .com sea la web relevante para cualquier búsqueda fuera de los países indicados (Perú, Mexico y Argentina) por lo que si un buscante hace la búsqueda en google.co (Google Colombia) lo que Google debería mostrarle es el resultado del dominio .com y no el dominio.pe, com.ar o com.mx), por eso el dominio.com es el que lleva los x-default.
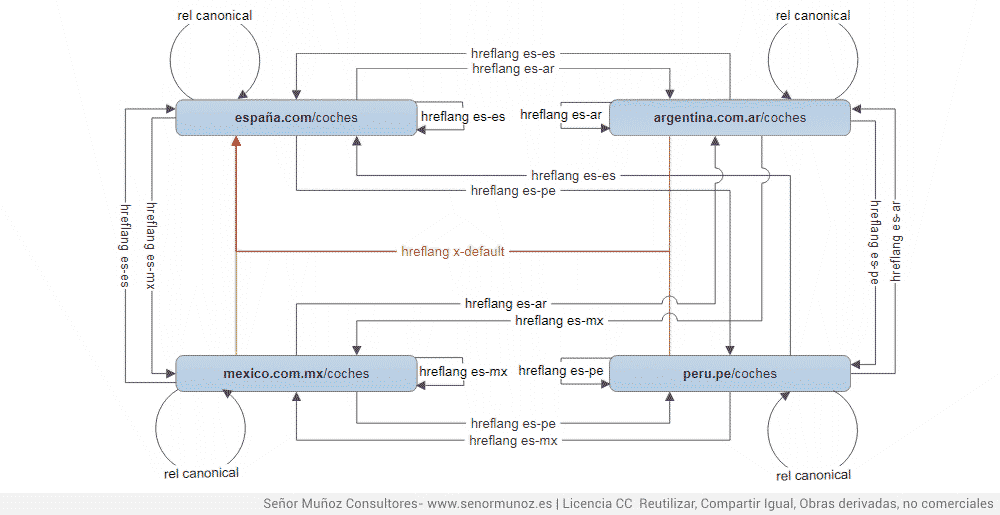
rel=canonical con el mismo idioma y diferentes paises mas x-default y hreflang
La clave está en que, como veis, todos los dominios, de nuevo, se autorenferencian con el canonical (como pasaba en el caso de que los contenidos fueran en otros idiomas).
El ensayo de distilled
En la prueba que distilled hizo resultaba que, si poníamos el canonical de todas las webs que copian el contenido de la URL original hacia esta URL original, los resultados en las SERPs del buscador eran:
- title de la URL original
- description de la URL original
- URL del país en el que se hacía la búsqueda, que tenía canonical a la versión original.
imaginemos un post escrito en la versión de España sobre el coche de Homer Simpson, el Plymouth Junkerolla de 1986. Como somos un medio distribuido, este contenido se publica, igual al 100% en Argentina y México. Cambiamos en los titles y descriptions Homer por Homero y coche por auto o carro. Eso es lo único que se hace.
Siguiendo el ejemplo anterior lo correcto sería que cada una de las versiones hiciera canonical a si misma, además del hreflang respectivo.
Pero en este caso decidimos apuntar con un canonical a la versión de España desde los posts de Argentina y México porque consideramos que es la versión original y el resto copias. Además, así, reforzaríamos la posición del post español, de la web español, que es la que nos interesa.
Este sería el ejemplo.
| España | Argentina | México | |
| Title | El mejor coche de la historia: Plymouth Junkerolla de 1986 | El mejor auto de la historia: Plymouth Junkerolla de 1986 | El mejor carro de la historia: Plymouth Junkerolla de 1986 |
| Description | Conoce la historia del mejor coche de la historia, el Plymouth Junkerolla de 1986, el coche de Homer Simpson | Conocé la historia del mejor auto de la historia, el Plymouth Junkerola de 1986, el auto de Homero Simpson | Conoce la historia del mejor carro de la historia, el Plymouth Junkerola de 1986, el auto de Homero Simpson |
| URL | españa.com/coches | argentina.com.ar/coches | mexico.com.mx/coches |
| Canonical | A si misma | españa.com/coches | españa.com/coches |
Según el ensayo, en este caso se producirían las siguientes opciones.
- Si el buscante está en España, le aparecerá la URL españa.com/coches con su title y su description.
- Si el buscante está en Argentina, le aparecerá el title y la description de la versión española pero la URL de la versión argentina.
- Si el buscante está en México, le aparecerá el title y la description de la versión española pero la URL de la versión mexicana.
Por eso es importante decidir correctamente como se establecen los canonicals.
El ensayo de Sergio Redondo
Así pues, mi compañero Sergio Redondo hizo el mismo test con similares resultados. Se trata de un test donde hemos probado a ver que ocurre cuando en un proyecto multipaís, el canonical no coincide con el hreflang de la versión local en la que estamos (es decir, los canonicals apuntan al contenido original)..
Resultado de la búsqueda en Google.es:
- Title de la URL que recibe el canonical (URL original)
- Description de la URL que recibe el canonical (URL original)
- URL de la versión local
- La caché que muestra es la caché de la página canónica, la que recibe el canonical
Además, un segundo experimento sobre el mismo trabajo: Cuando el hreflang x-default no coincide con la URL canónica nos muestra lo siguiente:
- Title de la URL que recibe el canonical (URL original)
- Description de la URL que recibe el canonical (URL original)
- URL del hrefllang x-default
- La caché que muestra es la caché de la página canónica.
4. Canonical con amp
4.1. amp
AMP (o Accelerated Mobile Pages) es una forma de mostrar los contenidos de tu página web de manera más rápida, ya que su objetivo es mejorar el rendimiento de las páginas (performance y velocidad) en el uso de la web desde dispositivos móviles. Está montado alrededor de 1) AMP HTML (componentes mínimos) 2) AMP JS (código javascript mínimo) y 3) cachés (a través de CDNs). Lo más relevante desde el punto de vista de este artículo es que sueles tener el contenido AMP en tu propio dominio, pero Google tiene su propia URL que es la que aparece en el bloque de news (que te hace un 302, por cierto)
4.2. Canonical + amp
No hay variación del objetivo, ya que la directiva canonical debe aplicarse igualmente y desde la desktop se debe apuntar a la amp. ¿Qué pasará con el índice mobile first cuando salga? Ni idea.
- versión amp apuntando canonical a la versión desktop
- versión desktop apuntando con directiva rel amphtml a la versión amp
- en caso que google muestre su URL (lo normal) esta, por defecto, tiene un canonical apuntando a la versión amp de nuestra web.
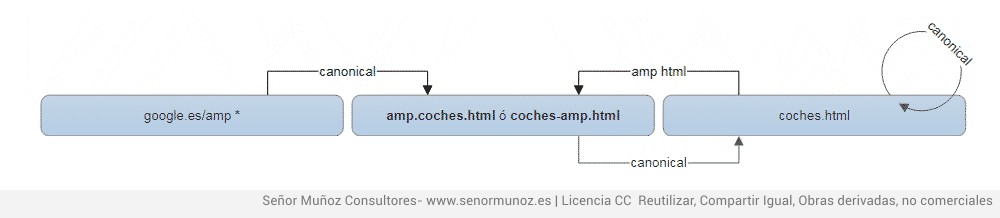
rel=canonical y amp html con la URL de google que aparece por defecto.
En el ejemplo se muestra qué hace la versión de amp de google (que es la que aparece desde las SERPs). Esta hace una redireccion 302 a la URL de canonical. No es relevante, ya que no tenemos nosotros control sobre ella.
5. Canonical con versión móvil
5.1. Versión móvil
Podemos tener una versión móvil de nuestra web, donde presentemos nuestro html optimizado para servicios móviles. Es una convención (ojo, no escrita, es como el clicar en el logo, que te lleva siempre a la home) que la versión móvil de una web esté en el subdominio m. del dominio principal, pero no es obligatorio (hasta otros dominios hemos visto para la versión móvil). En la versión móvil de la web deberá existir el mismo contenido, pero nos permiten ciertas licencias que en la versión desktop no: podemos esconder elementos (siempre que estén presentes)
5.2. móvil + canonical
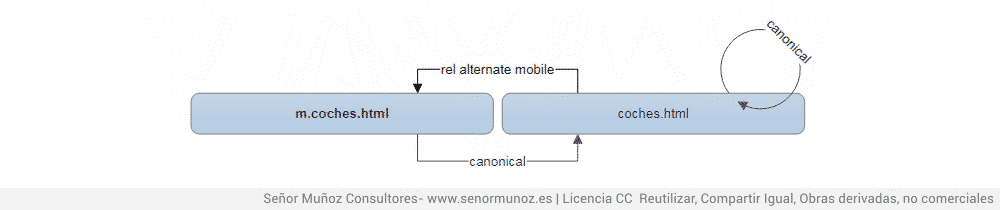
rel alternate mobile y rel=canonical
5.3. Canonical con amp y versión móvil
Una situación difícil de darse hoy en día, pero que si aparece, tiene fácil solución, ya que la URL de desktop tendría que apuntar con sus respectivos alternate (versión mobile y versión amp) a las URLs correspondientes y estas versiones, a su vez, apuntar mediante canonical a la desktop, ya que es la principal ¿Por qué no se referencian la versión mobile y la versión amp? Porque realmente la versión que debe tener los alternativos es la desktop. m.coches.html no es la versión alternativa móvil a amp.coches.html (ni viceversa).
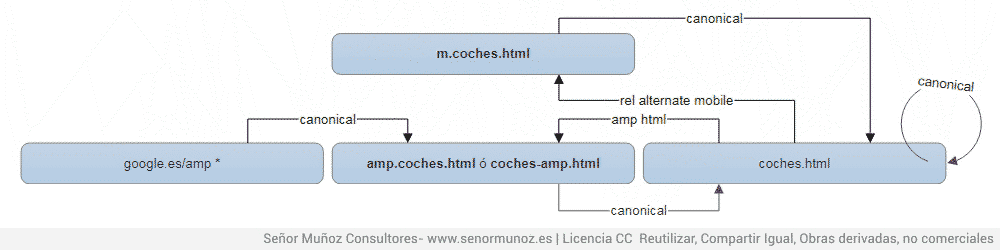
rel=»canonical», rel alternate mobille y rel amp html
6. Canonical con noindex
6.1. noindex
El noindex a nivel de meta le pide a Google que no indexe la URL. Se usa ante determinados contenidos que no nos interesa que se posicione, aquellos que no nos interesan que se indexen o ante una limpieza de URLs por panda, por ejemplo, para marcar aquellas URLs de baja calidad,…
6.2. noindex y canonical:
Entonces ¿Puedo unir la etiqueta noindex y la etiqueta canonical en la misma URL? Cuando unimos las dos etiquetas en la misma URL, estaremos dando una señal errónea al buscador: Ey, no me indexes pero, ey, yo soy la URL original. Si quereis mas info podéis revisar esta entrada del blog donde hablamos sobre qué pasó con la conjunción de noindex y canonical. Al tener un canonical lo que le estás diciendo al buscador es que las dos URLs son equivalentes (justo lo contrario del noindex).
El consejo es el siguiente: que no aparezcan en la misma URL, elegir una de las dos. Si quieres asegurarte la desindexación de una URL ya indexada, quítale el canonical y márcala con un noindex. Si tienes urls diferentes (dos o más) y el contenido es 100% igual te interesa insertar el canonical y si tienes URLs que no te interesan que se indexen, usa el noindex.
7. Canonical con robots.txt
En este tipo de unificación se suele hablar de bloquear mediante el robots.txt determinadas URLs. Es decir, meter en el robots.txt un disallow:/algunaCarpeta
Al igual que en el punto anterior, no se recomienda unir la directiva disallow del robots.txt al canonical. Si hemos de poner una directiva canonical en una determinada URL es porque presenta una situación de duplicación de contenidos. Pero si impedimos al robot acceder a esa URL, no conseguiremos que sepa que ahí hay un contenido que queremos «canonicalizar» a alguna URL. Si marcamos la URL con noindex mediante robots.txt o impedimos al buscador acceder a esa URL, esa URL, que puede estar ya indexada por Google, aún ranquee por una determinada keyword.
7.1. Anexo: ¿Disallow previene de indexación?
Tener una etiqueta noindex no impide a los buscadores la indexación. En el siguiente ejemplo veis una muestra de lo que os estamos contando. Esta URL tiene un noindex marcado, hace un metarefresh y un 302 a la nueva URL, pero está rankeando (seguramente por la autoridad del sitio) Reescribo y actualizo: 20 de Julio del 2017, que en los comentarios (gracias Christian, gracias Jose María, gracias Kico) están diciendo cosas completamente lógicas. Modifico el título a «Disallow» (antes ponía noindex)
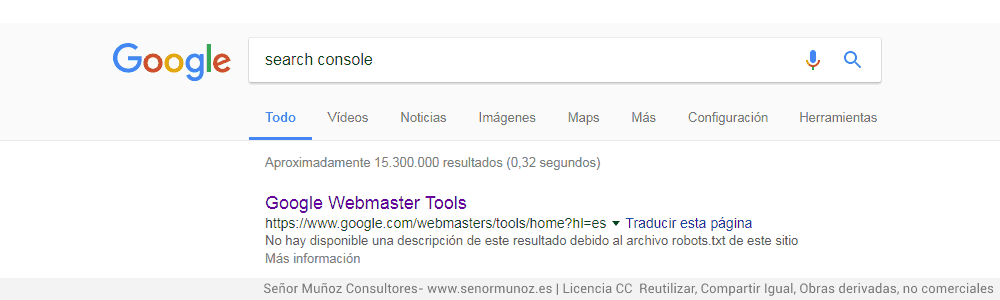
URL con disallow y ranqueando en Google
Esta URL está bloqueada mediante el robots.txt. Es decir: google no puede acceder a ella. Por lo que si quisiéramos usar un canonical aquí google no podría verlo.
En el caso que quisieramos canonicalizar esta URL a otra tendríamos que 1) Poner en esta URL la directiva canonical 2) Quitar el disallow para que Google entre 3) Que google actualice su caché y descubra el canonical a la URL correcta. Y cuando descubramos que google ya muestra la URL original entonces 4) pondríamos de nuevo el disallow.
Y si ella fuera la original y tuviera que autoreferenciarse con el canonical no conseguiríamos sacarla del índice (porque es la original)
Articulazo, Fernando! Directo a favoritos 🙂
Sólo un apunte: en el punto 7.1, el ejemplo es erróneo:
a) Esa URL (la de Search Console) posiciona porque al estar bloqueada por robots.txt, Google no puede ver lo que sea que haya detrás (ya sea noindex, canonical a otra, 301 o 302, incluso un 404) y como tiene enlaces, la indexa.
b) Si Google modificase su robots.txt para eliminar la línea que bloquea esa URL, al crawlear la URL se encontraría con un 302 (si no estás logado, te redirige a la página de login de Google), que, esa sí, lleva un noindex. Desconozco qué haría exactamente el bot con ese lío, aunque imagino que siendo una URL popular (con enlaces) y la redirección una 302, probablemente la posicionase igual.
Hace poco hubo un hilo en twitter porque la URL no aparecía, en cualquier caso, pero creo que han hecho cambios desde entonces: https://twitter.com/ramesh_s_bisht/status/880029854170726400
Hola Christian, gracias por tu comentario y por tu aporte. Mensajes que mejoran el post, sin duda.
Mis 2 cts. Creo que tienes razón, pero creo que no me quita la mia. Me explico. Como vemos, la URL de google está bloqueada, via disallow y via . Lo que yo digo es que «Tener una etiqueta noindex no impide a los buscadores la no indexación» (y así lo dijo Gary Illyes «Robots.txt disallow does not prevent indexing».
Abrazo grande!
Sí y no 🙂
“Robots.txt disallow does not prevent indexing” => correcto, el robots.txt impide el crawling, pero no el indexado. Una URL bloqueada en robots.txt, no será crawleada (Google no podrá extraer su contenido – title, description, canonical, noindex, etc. -) pero sí indexada e incluso rankeada si otras circunstancias se dan (por ejemplo, muchos enlaces externos).
Por otro lado, el noindex (la etiqueta meta robots con noindex) sí que hace que no se indexe una página, SIEMPRE Y CUANDO Google pueda ver esa etiqueta y la haya visto. Si la URL con el noindex está bloqueada en robots.txt, es como una URL sin noindex. Del mismo modo, si hemos incluido la etiqueta noindex pero la URL todavía no ha sido crawleada, seguirá en el índice.
Creo que hay muchísima confusión entre todo este tipo de «mecanismos» (el más común es usar el robots.txt para evitar indexación)
Abrazo, Fernando!
He de reconocer que hay que quitarse el sombrero ante este señor artículo, fácil y para toda la familia jeje 😀 Hablando en serio, muy buenas gráficas explicativas. Me ha servido para profundizar y asimilar mejor aspectos que muchas veces pasaba por alto. Como ya lo hacían los CMS que uso normalmente de manera automática… Seguramente este conocimiento que gracias a tu artículo ahora tengo más asimilado me sirva más adelante. Muchas gracias por publicarlo! 😉
En cuanto a lo que habláis en los comentarios, sí es cierto que dices: «Tener una etiqueta noindex no impide a los buscadores la indexación», y es verdad. Sin embargo, con el texto que viene a continuación en el artículo:
«En el siguiente ejemplo veis una muestra de lo que os estamos contando. Esta URL tiene un noindex marcado, hace un metarefresh y un 302 a la nueva URL, pero está rankeando (seguramente por la autoridad del sitio)»
El hecho de limitarte a decir solo eso y no añadir que es porque está bloqueado por robots.txt, da lugar a la confusión… Yo creo que una página que desde un inicio tiene meta robots noindex y nunca ha tenido un dilallow en robots.txt, no indexará nunca, a no ser que suceda algo raro. De la misma manera, si ya estaba indexada y le añadimos un meta robots noindex, e importante GoogleBot la puede crawlear siempre. En ese caso, acabará desindexando (lo hará más pronto si NO tiene un canonical a sí misma 😉 )
Muy de acuerdo Jose María. Gracias por tu mensaje y por la aclaración